Gravitationsgleichung
In dieser Einheit schauen wir uns näher an, welche Faktoren den bilateralen Handel zwischen Ländern beeinflussen.
Vorlesung
Anwendung
Ziel der Anwendung heute ist es, sich zunächst mit der Programmiersprache R vertraut zu machen und dann die grafische Analyse der Vorlesung zu replizieren.
R, RStudio und Rstudio.Cloud
Im Folgenden benutzen wir die Programmiersprache R und die RStudio Umgebung. Diese können entweder im Browser unter
RStudio.Cloud benutzt werden, oder natürlich lokal auf dem eigenen Computer. Dafür muss man hier zunächst
R und dann
RStudio downloaden und installieren.1
Für die “R Basics” oder einen Refresher empfiehlt sich u.a. Grant McDermotts
R Intro (auf Englisch). Eine interaktive Alternative ist
swirl, ein Paket mit dem man R in R lernen kann.
Los geht’s
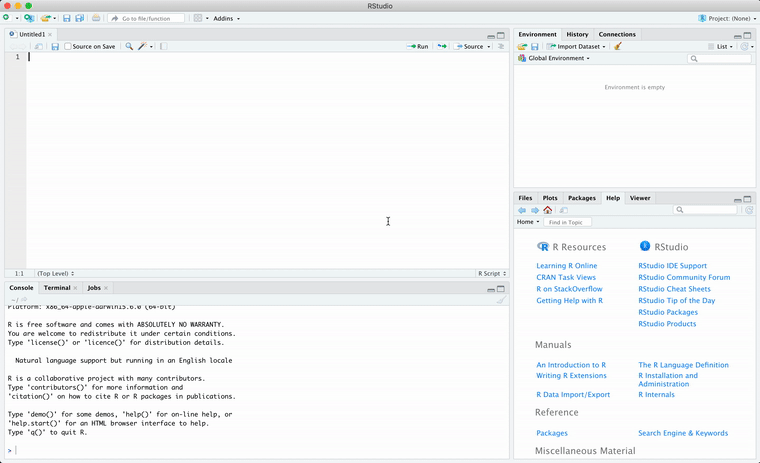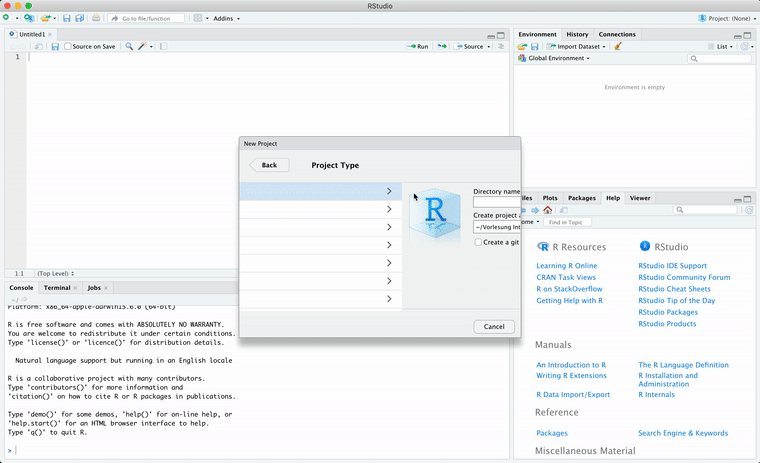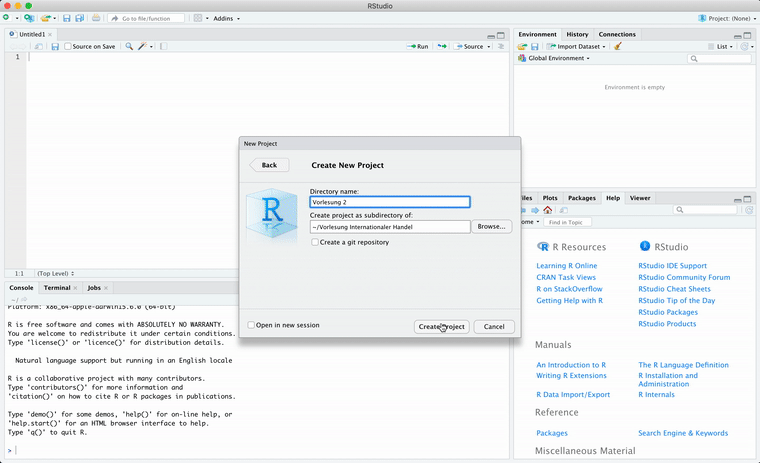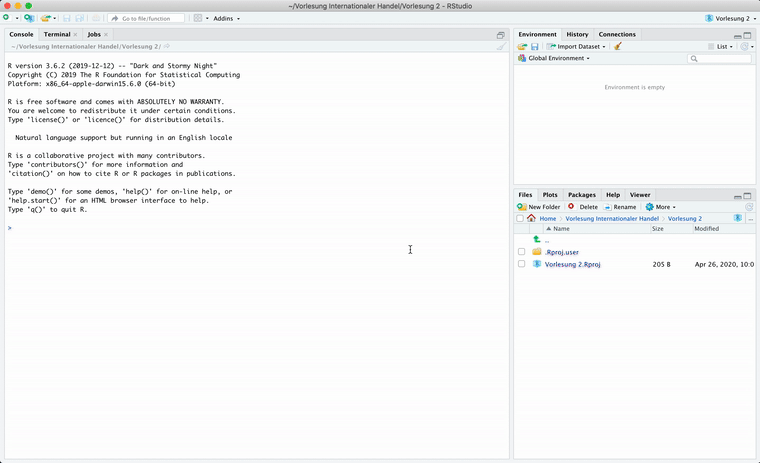
Das RStudio nun öffnen und zuerst ein neues Projekt anlegen, z.B. mit dem Titel “Vorlesung 2”:
Im R Projekt Ordner empfehle ich drei Ordner anzulegen:
- “input”: Hierein kommen die Daten
- “output”: Hier wird der Output gespeichert, z.B. Grafiken und Tabellen
- “code”: Hier kommt der Code rein
- manchmal “temp”: bei rechenintensiven Problemen lohnt es sich manchmal zwischenzuspeichern, das kommt hier rein.
Die in der Vorlesung verwendeten Daten sind die folgenden:
- trade_data.rds: Bilaterale Handelsdaten von UN Comtrade aus dem Jahr 2015
- gravity_data.rds: Bilaterale Gravity-Variablen vom CEPII, ursprünglich aus Head & Mayer (2014)2
Die sollten in den Ordner “input” gespeichert werden.
Packages installieren und laden
Zwar kann “out-of-the-box” schon einiges, aber wirklich mächtig wird R durch zusätzliche Packages. Wir werden immer wieder auf einige Standardpakete zurückgreifen:
- data.table: für schnelle Datenmanipulation
- ggplot2: für Visualisierungen
- readr, stringr, …: einige Pakete aus dem so genannten Tidyverse, einer Gruppe von engverwandten Paketen mit häufig sehr intuitiver Syntax
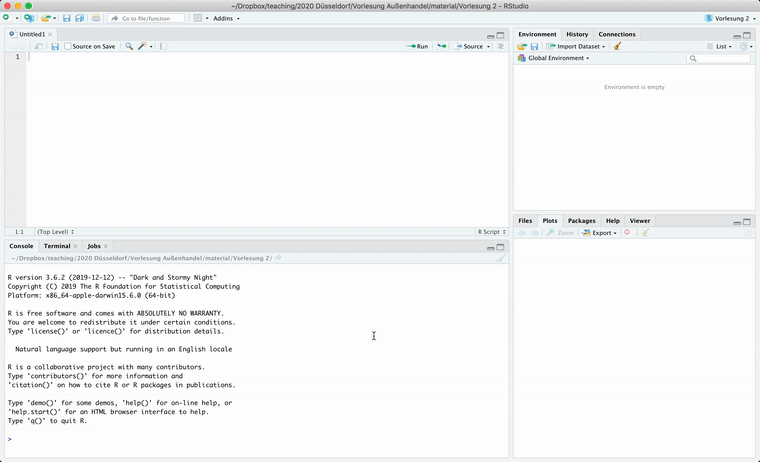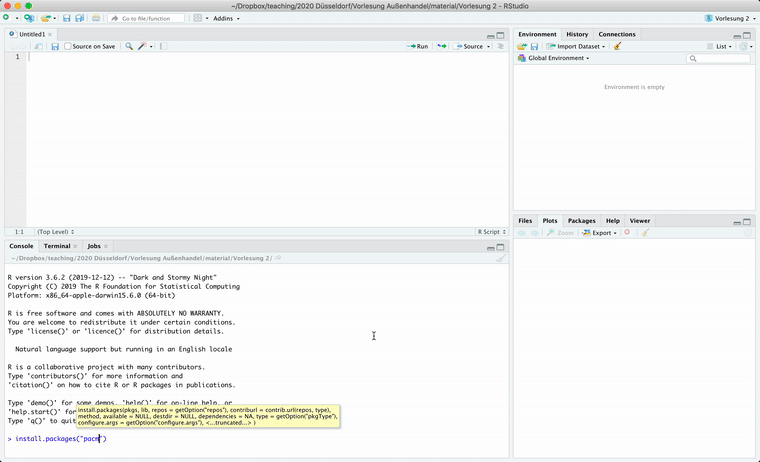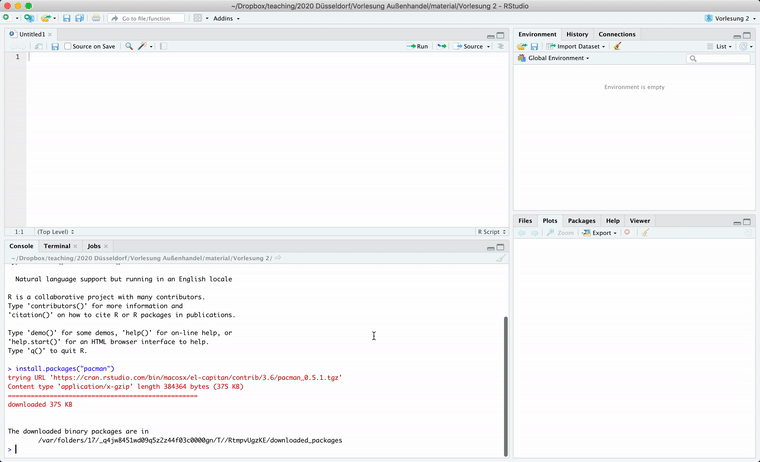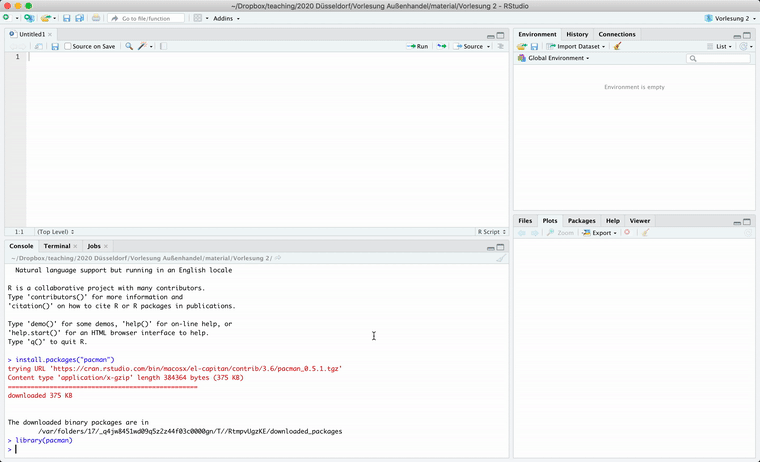
Ich empfehle zudem das Paket pacman, dass das Management von Paketen erheblich vereinfacht. Hierzu einfach einmal in der Konsole folgenden Code ausführen:
install.packages("pacman")
library(pacman)
Also so:
Ab jetzt können andere Pakete einfach mit p_load(...) installiert, bzw. geladen werden:
p_load(data.table)
p_load(ggplot2)
p_load(readr)
p_load(stringr)
Wir werden später noch andere Pakete laden, brauchen aber zunächst nur diese. Grundsätzlich empfiehlt es sich aber, alle benötigen Pakete zu Beginn der Datei zu laden.
Daten laden und mergen
Jetzt geht es an die Daten. Wir laden beide Datensätze, subsetten und passen die Variablennamen so an, dass beide gemerget werden können. Bei den Handelsdaten gibt es (mindestens) zwei “flows”: flow == 1 sind Importdaten, flow == 2 sind Exportdaten, aus Sicht des “reporting country”. D.h. bei flow == 1 ist der reporter das Ursprungsland, partner ist das Zielland des Handelsstroms.3
# Handelsdaten laden und subsetten
data_trade = read_rds("input/trade_data.rds")
data_trade = data_trade[flow == 1, .(iso_o = partner, iso_d = reporter, value)]
data_trade = data_trade[iso_o != iso_d]
# Gravity-Daten laden und subsetten
data_gravity = read_rds("input/gravity_data.rds")
data_gravity = data_gravity[year == 2015]
setnames(data_gravity, c("iso3_o", "iso3_d"), c("iso_o", "iso_d"))
# mergen anhand von "iso_o" und "iso_d"
data = merge(data_gravity, data_trade, by = c("iso_o", "iso_d"))
Wir haben nun einen Datensatz, data, der die Gravity-Variablen und die Handelsströme zusammen bringt. An dieser Stelle lohnt es sich, ein bisschen die unterschiedlichen Variablen des Datensatzes näher anzuschauen und möglicherweise einige davon zu plotten:
head(data)
histogram(data$value)
# ...
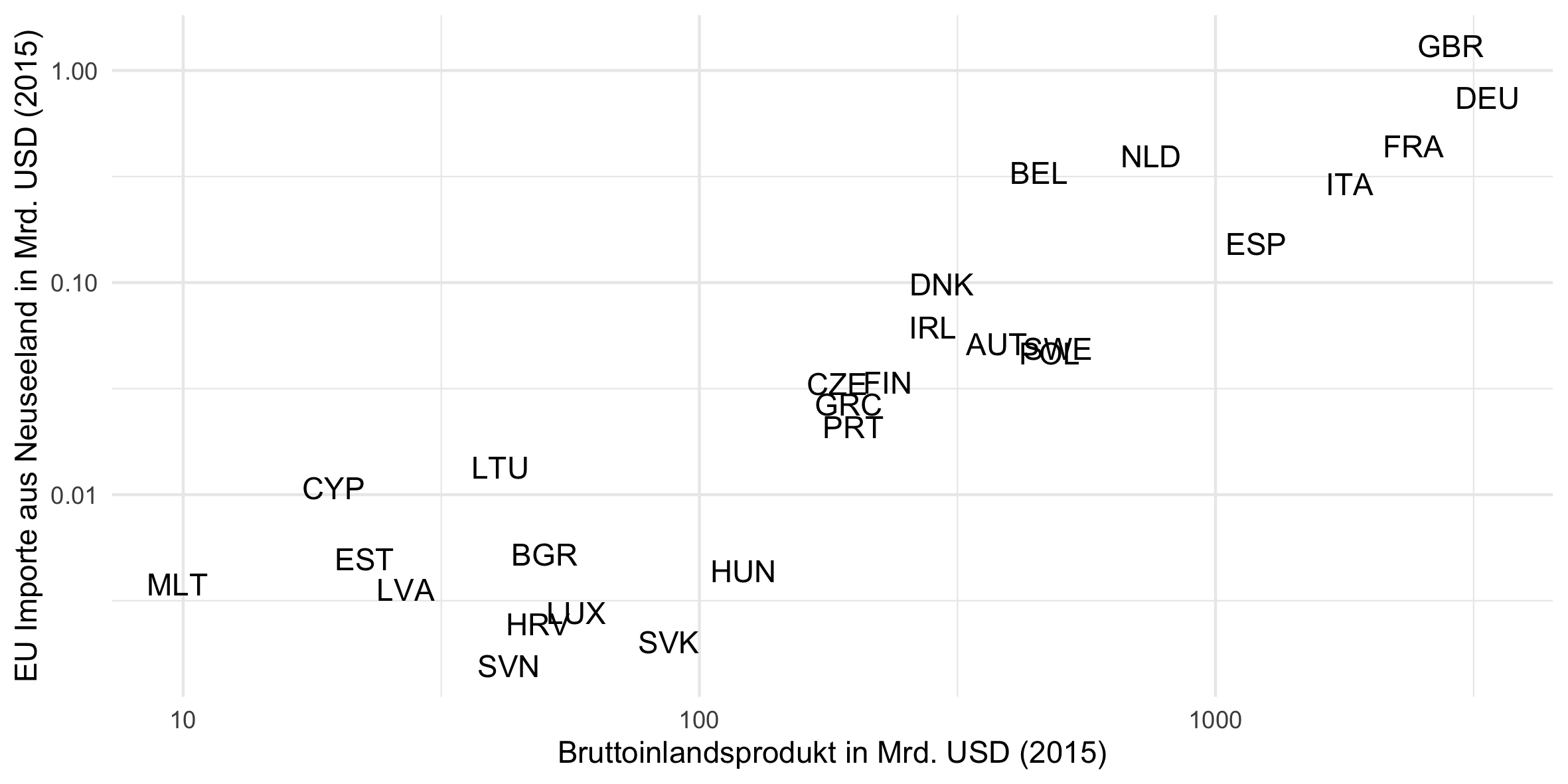
Handel und Größe
Die erste Plot in der Vorlesung zeigt den Einfluss von wirtschaftlicher Größe eines Landes auf den bilateralen Handel. Das Beispiel waren Importe von EU Ländern aus Neuseeland. Wir subsetten also Handelsstöme deren Ursprungsland Neuseeland ist, also data[iso_o == "NZL"], und deren Zielland ein EU Mitgliedsstaaat ist, also data[eu_d == T].4
# Exporte von Neuseeland in die EU in Milliarden vs. BIP des Ziellandes in Milliarden
# Daten vorbereiten
plot_data = data[iso_o == "NZL" & eu_d == T]
plot_data[, value := value / 1000000000]
plot_data[, gdp_d := gdp_d / 1000000000]
plot_data = plot_data[, .(iso_d, value, gdp_d)]
# Plotten
plot = ggplot(plot_data) +
theme_minimal() +
geom_text(aes(x = gdp_d, y = value, label = iso_d)) +
scale_x_log10("Bruttoinlandsprodukt in Mrd. USD (2015)") +
scale_y_log10("EU Importe aus Neuseeland in Mrd. USD (2015)")
print(plot)
Wir können noch eine lineare Regression in die Grafik legen und die Ländernamen durch Punkte ersetzen:
# Exporte von Neuseeland in die EU in Milliarden vs. BIP des Ziellandes in Milliarden
# Daten vorbereiten
plot_data = data[iso_o == "NZL" & eu_d == T]
plot_data[, value := value / 1000000000]
plot_data[, gdp_d := gdp_d / 1000000000]
plot_data = plot_data[, .(iso_d, value, gdp_d)]
reg_info = lm(log10(value) ~ log10(gdp_d), data = plot_data)$coefficients
# Plotten
plot = ggplot(plot_data) +
theme_minimal() +
geom_point(aes(x = gdp_d, y = value)) +
geom_abline(intercept = reg_info[[1]], slope = reg_info[[2]], alpha = 0.5, color = "red") +
scale_x_log10("Bruttoinlandsprodukt in Mrd. USD (2015)") +
scale_y_log10("EU Importe aus Neuseeland in Mrd. USD (2015)")
print(plot)
# Plot speichern
ggsave(plot, filename = "output/gdp_imports.png", width = 20, height = 10, units = "cm")
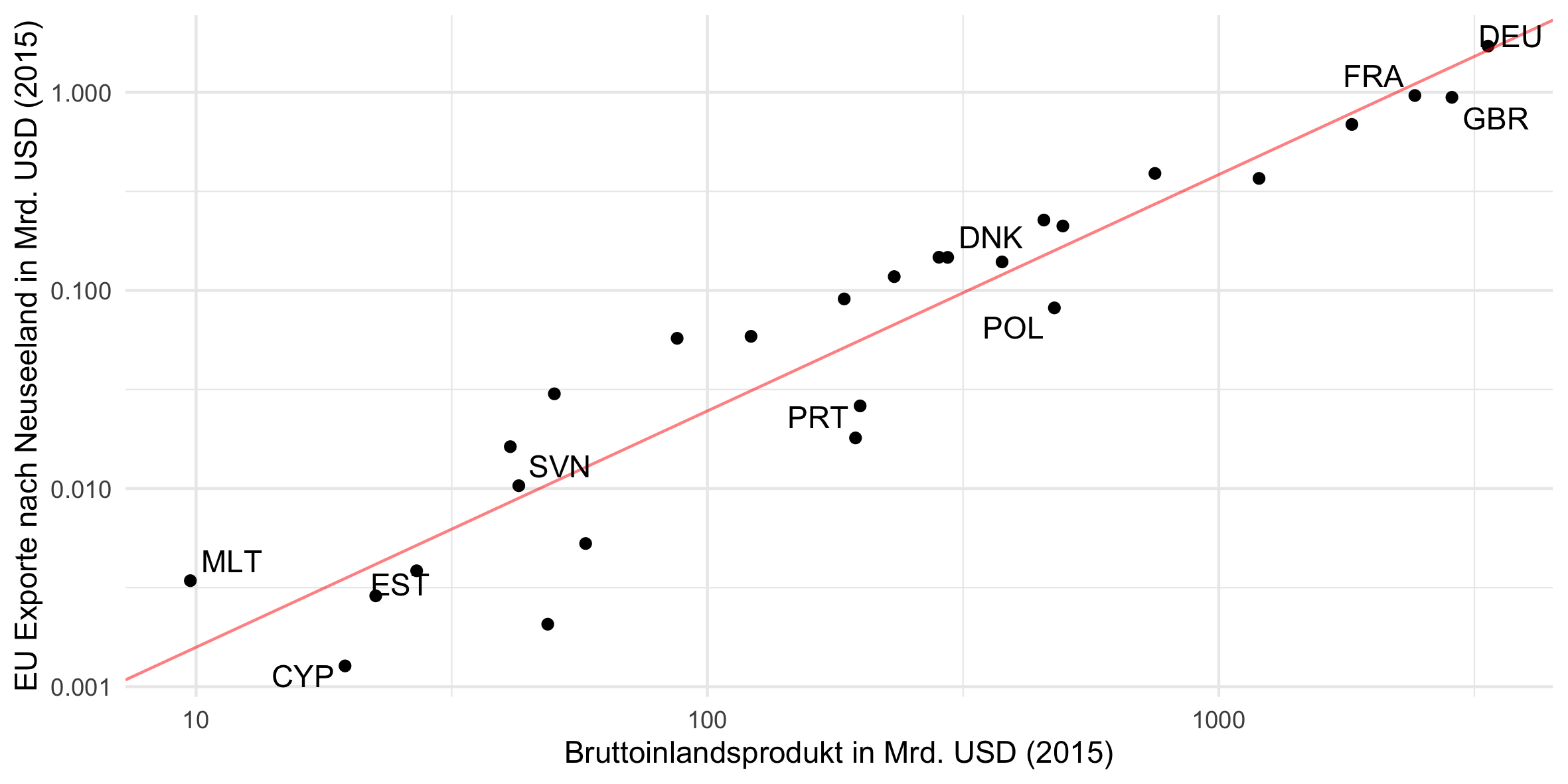
Die Grafik für die entgegengesetzten Handelsströme lässt sich leicht analog produzieren:5
# Exporte von EU Ländern nach Neuseeland
# zusätzliche Pakete laden
p_load(ggrepel)
p_load(countrycode)
# Daten vorbereiten
plot_data = data[iso_d == "NZL" & eu_o == T]
plot_data[, value := value / 1000000000]
plot_data[, gdp_o := gdp_o / 1000000000]
plot_data[, interesting_country := ""]
plot_data[iso_o %in% c("DEU", "FRA", "GBR", "MLT", "EST", "CYP", "PRT", "POL", "DNK", "SVN"),
interesting_country := iso_o]
plot_data = plot_data[, .(iso_o, value, gdp_o, interesting_country)]
reg_info = lm(log10(value) ~ log10(gdp_o), data = plot_data)$coefficients
# Plotten
plot = ggplot(plot_data) +
theme_minimal() +
geom_point(aes(x = gdp_o, y = value)) +
geom_abline(intercept = reg_info[[1]], slope = reg_info[[2]], alpha = 0.5, color = "red") +
geom_text_repel(aes(x = gdp_o, y = value, label = interesting_country)) +
scale_x_log10("Bruttoinlandsprodukt in Mrd. USD (2015)") +
scale_y_log10("EU Exporte nach Neuseeland in Mrd. USD (2015)")
print(plot)
# Plot speichern
ggsave(plot, filename = "output/gdp_exports.png", width = 20, height = 10, units = "cm")
Handel und Distanz
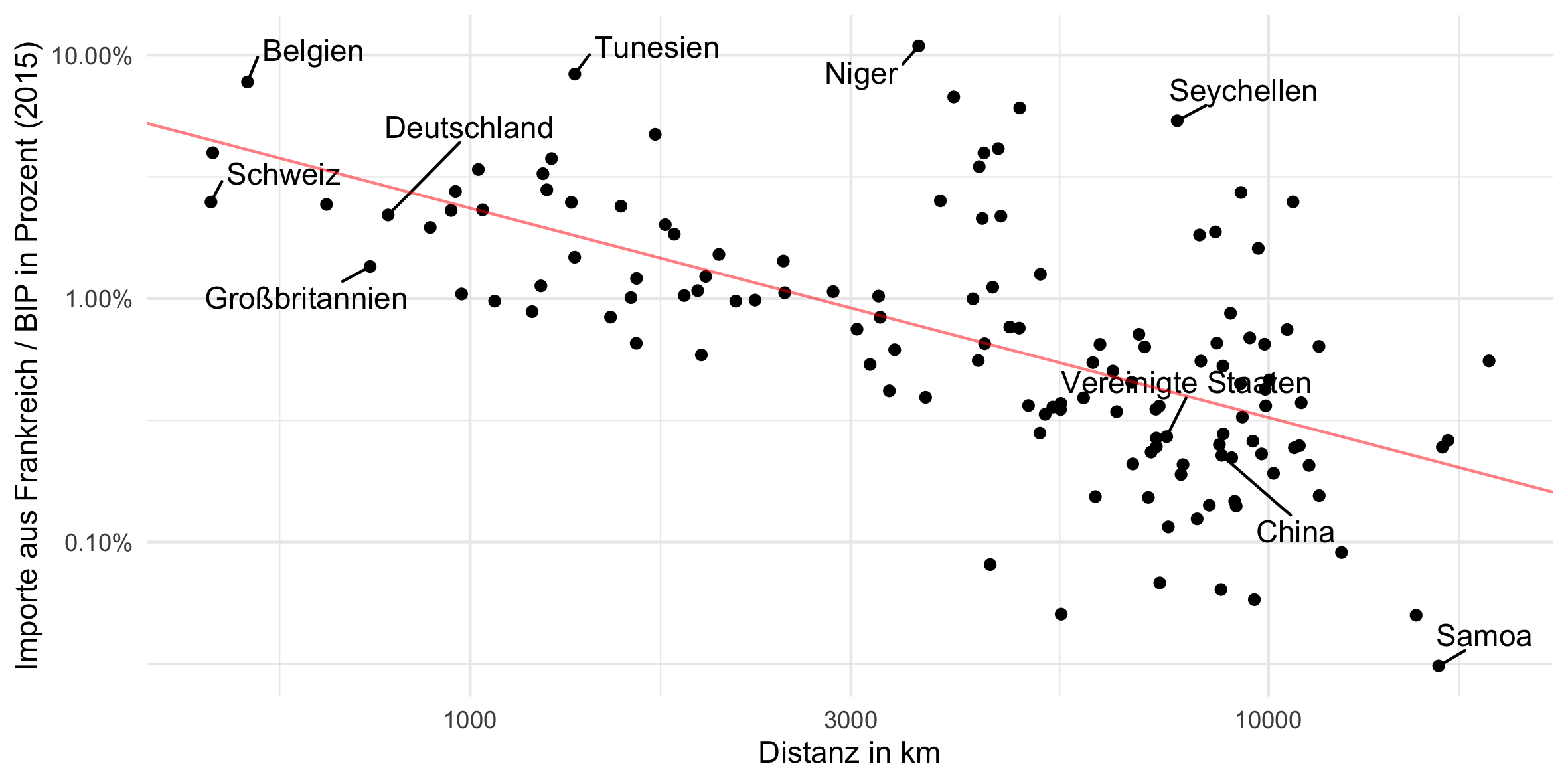
Der nächste Plot in der Vorlesung zeigt den Einfluss von Distanz auf den bilateralen Handel zweier Länder, anhand des Beispiels von Frankreich. Wir subsetten nun also die Daten und wählen nur solche aus, deren Ursprungsland Frankreich ist mit data[iso_o == "FRA"]. Danach normieren wir den jeweiligen Handelsstrom mit dem BIP des Ziellandes.6
# Französische Exporte und Distanz zu Zielländern
# zusätzliche Pakete laden
p_load(scales)
# Daten vorbereiten
plot_data = data[iso_o == "FRA"]
plot_data[, value_gdp_d := value / gdp_d]
plot_data[, ratio := value_gdp_d / distw]
plot_data[, interesting_country := ""]
plot_data[iso_d %in% c("GBR", "BEL", "CHE", "FRA", "USA", "TUN", "CHN", "SYC", "DEU", "NER", "WSM"),
interesting_country := countrycode(iso_d, "iso3c", "country.name.de")]
plot_data = plot_data[, .(iso_d, distw, value_gdp_d, ratio, interesting_country)]
reg_info = lm(log10(value_gdp_d) ~ log10(distw), data = plot_data)$coefficients
# Plotten
plot = ggplot(plot_data) +
theme_minimal() +
geom_point(aes(x = distw, y = value_gdp_d)) +
geom_text_repel(aes(x = distw, y = value_gdp_d, label = interesting_country),
seed = 120817, force = 10, box.padding = 0.5) +
geom_abline(intercept = reg_info[[1]], slope = reg_info[[2]], color = "red", alpha = 0.5) +
scale_x_log10("Distanz in km", label = period) +
scale_y_log10("Importe aus Frankreich / BIP in Prozent (2015)", label = percent)
print(plot)
# Plot speichern
ggsave(plot, filename = "output/distance_imports.png", width = 20, height = 10, units = "cm")
Erste Gravity Schätzungen
Abschließend machen wir nun zwei erste Gravity Schätzungen. Neben der wirtschaftlichen Größe und der bilateralen Distanz zwischen den handelnden Ländern hat sich gezeigt, dass auch andere Einflüsse maßgeblich sind: Darunter Sprache, gemeinsame Währung, koloniale Geschichte, aber natürlich auch klassische Handelspolitik in Form eines Freihandelsabkommens.
In einem linearen Model können wir das in Form einer “naiven” Gravitationsgleichung schätzen:
# Naive Gravity Schätzung
# Lineare Schätzung
reg_naive_gravity = lm(log(value) ~ log(gdp_o) + log(gdp_d) + log(distw) + comlang_off + colony + comcur + fta_wto, data = data)
# Schätzergebnisse anzeigen
summary(reg_naive_gravity)
Der Output sollte in etwa so aussehen:
Call:
lm(formula = log(value) ~ log(gdp_o) + log(gdp_d) + log(distw) +
comlang_off + colony + comcur + fta_wto, data = data)
Residuals:
Min 1Q Median 3Q Max
-14.1593 -1.2473 0.2631 1.5594 12.7240
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -32.981651 0.389998 -84.569 < 2e-16 ***
log(gdp_o) 1.316497 0.008427 156.230 < 2e-16 ***
log(gdp_d) 1.062933 0.008940 118.899 < 2e-16 ***
log(distw) -1.342179 0.025887 -51.847 < 2e-16 ***
comlang_off 1.055214 0.055149 19.134 < 2e-16 ***
colony 0.579088 0.147468 3.927 8.64e-05 ***
comcur 0.412668 0.153390 2.690 0.007144 **
eu 0.460684 0.122299 3.767 0.000166 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.554 on 19017 degrees of freedom
(3352 observations deleted due to missingness)
Multiple R-squared: 0.6726, Adjusted R-squared: 0.6725
F-statistic: 5582 on 7 and 19017 DF, p-value: < 2.2e-16
Alternativ kan man ein generelles Gravitationsmodell schätzen:
p_load(lfe)
# Lineare Schätzung mit fixed effects
reg_gen_gravity = felm(log(value) ~ log(distw) + comlang_off + colony + comcur + fta_wto | iso_o + iso_d, data = data)
# Schätzergebnisse anzeigen
summary(reg_gen_gravity)
Der Output in der Konsole sollte etwa so aussehen:
Call:
felm(formula = log(value) ~ log(distw) + comlang_off + colony +
comcur + fta_wto | iso_o + iso_d, data = data)
Residuals:
Min 1Q Median 3Q Max
-11.7004 -1.1679 0.0971 1.2699 9.9312
Coefficients:
Estimate Std. Error t value Pr(>|t|)
log(distw) -1.52100 0.02538 -59.920 < 2e-16 ***
comlang_off 1.05592 0.05225 20.208 < 2e-16 ***
colony 0.74704 0.13074 5.714 1.12e-08 ***
comcur -0.19122 0.12040 -1.588 0.112
fta_wto 0.52679 0.04975 10.589 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.233 on 22020 degrees of freedom
Multiple R-squared(full model): 0.7667 Adjusted R-squared: 0.763
Multiple R-squared(proj model): 0.2361 Adjusted R-squared: 0.2238
F-statistic(full model):203.3 on 356 and 22020 DF, p-value: < 2.2e-16
F-statistic(proj model): 1362 on 5 and 22020 DF, p-value: < 2.2e-16
Wir werden in den kommenden Wochen noch mehr solcher Schätzungen machen, und dabei immer wieder auf diese (oder vergleichbare) Schätzungen von “naiven” und generellen Gravitationsgleichungen zurückkommen.
One more thing
In der Vorlesung gab es eine (vereinfachte) Schätzung des möglichen Brexit-Effekts anhand dieser vorliegenden Daten. Können Sie diese replizieren? Schicken Sie mir Ihre Grafik und den Code dazu, und ich schicke Ihnen meine “Musterlösung”. Für diejenigen, die soweit nicht gekommen sind, werde ich den Code in der kommenden Woche hier posten.
Wenn es etwas technischer werden darf, sind Grants Folien zu den Grundlagen der R Sprache sehr zu empfehlen: R language basics. ↩︎
Head, K. and T. Mayer, (2014), “Gravity Equations: Toolkit, Cookbook, Workhorse.” Handbook of International Economics, Vol. 4,eds. Gopinath, Helpman, and Rogoff, Elsevier. ↩︎
Länder sind in diesem Datensatz mit einem so genannten “ ISO 3166-1 alpha-3” country code gekennzeichnet, d.h. “DEU” ist Deutschland, “FRA” ist Frankreich, und so weiter. ↩︎
Die Variable
eu_dist eine der Variablen aus dem Gravity-Datensatz die die EU Mitgliedschaft des Ziellandes kennzeichnet, eine Alternative wäre hier “manuell” die EU Länder auszuwählen, alsodata[eu_d %in% c("DEU", "FRA", "NLD", "ITA",...)]und so weiter. ↩︎Das ggrepel Paket sorgt dafür, dass die Ländernamen nicht direkt auf den Punkten sind. countrycode “übersetzt” country codes in andere country codes, und aber auch Ländernamen. ↩︎
scales ermöglicht differenziertere x- und y-Achsen in ggplot2 Plots. ↩︎